La compilation objets
1 Introduction
Les langages orientés objets introduisent des concepts comme l’héritage et le polymorphisme dans les langages de programmation. Dans ce document on va essayer de voir comment ces concepts peuvent être réalisés dans les compilateurs.
Les langages objets enrichissent la sémantique des langages mais ne modifient en rien les aspects de la compilation par rapport aux langages non objet. Ils ne font que rajouter une « couche » au-dessus de ceux-ci.
On peut donc tout à fait en implémenter les concepts avec des langages comme le C au prix d’une certaine rigueur de développement et de notation. Évidemment on ne bénéficie pas des facilitées de notation de ceux-ci ni des possibilités de vérification de typage fort des langages objets.
Néanmoins on peut utiliser les autres langages pour comprendre ce que fait un compilateur objet. C’est ce que nous allons faire en utilisant le langage C. On va implémenter tout les concepts de la programmation orientée objets sans langage objet.
Tout au long de cet article, je me réfère à mes propres expériences et nullement à ce qui est fait dans un langage de programmation précis.
2 Les objets
2.1 Qu’est ce qu’un objet
Un objet n’est rien de plus que des variables appelées attributs et des fonctions appelées méthodes qui permettent la manipulation des variables. C’est une unité logique qui permet au programmeur de regrouper/classifier le code des programmes.
En théorie, on ne devrait pouvoir manipuler les attributs qu’en passant par les méthodes. C’est ce que l’on appelle l’encapsulage. Ceci à pour but de garantir l’intégrité des attributs. En effet Le programmeur qui défini un objet et sûr que personne à par lui ne peut le modifier et donc qu’il n’a à se soucier que de la cohérence entre les différentes méthodes qu’il fournit. En réalité, la plupart des langages objets autorisent la manipulation directe des attributs pour de simples raisons de performance.
Par objet on désigne la zone mémoire qui contient tout ce qui caractérise l’objet pendant l’exécution. On peut toujours créer plusieurs objets d’un même type (même interprétation mais pas même valeur des attributs par exemple). On appelle le type d’un objet une classe. C’est le moule qui définit ce que contient un type d’objet (type des attributs, type des méthodes et leurs implémentations si il y en a une). C’est ce qui est défini par le programmeur.
2.2 L’héritage
Dans un souci de simplification de la programmation. Les langages objets introduisent l’héritage. C’est la possibilité de repartir d’une classe déjà définie et d’en étendre ou modifier les fonctionnalités. Ce qui revient à pouvoir ajouter des attributs, des méthodes et/ou modifier certaine méthodes d’une classe pour en créer une autre. C’est la possibilité de réutiliser le code de manière simple.
2.3 Le polymorphisme
Le polymorphisme c’est la propriété pour un objet de revêtir plusieurs formes. Ce qui veut dire qu’un objet appartenant à une certaine classe doit pouvoir être vu comme un objet appartenant à n’importe qu’elle classe dont hérite sa classe. Un objet peut alors être vu de différentes façons. En effet, chaque classe ne fait que rajouter des attributs, des méthodes aux classes dont elle hérite. Il est donc normal que l’on puisse voir un objet sous forme plus restreinte qu’il n’est (qui peut le plus peut le moins). Ceci veut dire que toutes les méthodes qui sont capables de manipuler des objets d’une certaine classe doivent pouvoir manipuler des objets de n’importe quelle classe qui hérite de cette classe et ceci de manière transparente (on ne doit pas avoir la connaissance des classes qui héritent).
2.4 La surcharge
La surcharge c’est la possibilité de redéfinir des méthodes définies dans les classes parentes. Évidemment la méthode surchargée doit avoir les mêmes types de paramètres et le même type de valeur retournée.
Cela revient à dire que lorsque l’on exécute une méthode d’un objet on ne sait pas quel code sera vraiment exécuté grâce au polymorphisme. En effet, lorsque l’on manipule un objet comme un objet appartenant à une certaine classe, cet objet peut être un objet appartenant en fait à une classe qui hérite mais on ne connaît pas cette information (on ne veut pas savoir). Lorsque l’on exécute une méthode de l’objet, ce n’est peut être plus alors un objet de la classe que l’on considère mais un qui hérite de cette classe et qui a surchargé cette méthode. On ne connaît pas alors la méthode appelée (ce n’est pas forcément celle définie dans la classe considérée). Ce mécanisme rend le polymorphisme très riche et très souple mais la compilation plus compliquée (on perd une information statique et on gagne en souplesse à l’exécution).
2.5 Les classes abstraites
Imaginons que dans une classe on ait besoin d’une méthode mais dont on ne peut pas donner l’implémentation. C’est donc les classes qui héritent qui tôt ou tard devront implémenter cette méthode qui pourra néanmoins être utilisée par tout ceux qui voient cet objet au niveau de notre classe. C’est le même mécanisme que la surcharge qui va permettre aux classes qui héritent de faire correspondre le code à la méthode non implémentée. Si on ne parle pas de surcharge c’est juste parce que la méthode n’ayant pas été définie auparavant le terme ne convient pas. Pour ce type de méthode, on parle de méthodes abstraites. Une classe qui contient une ou plusieurs méthodes abstraites est appelée classe abstraite car un objet de cette classe serait incomplet. On ne peut donc pas créer d’objet de cette classe. On ne pourra créer des objets que des classes qui héritent et qui n’auront plus de méthodes abstraites.
On arrive alors à un nouveau concept. Les interfaces. Une interface est une classe qui ne contient que des méthodes abstraites. Il s’agit alors que d’une spécification de ce qu’il faut faire.
2.6 Les signaux
Le principe des signaux c’est d’informer les objets intéressés qui se sont auparavant abonnés à un signal d’un objet, quand l’événement se produit. C’est quelque chose de très pratique dans la programmation événementielle. Je ne connais pas de langages de programmation qui implémente ceci et c’est bien dommage. Voilà c’était mon coup de gueule. La seule chose que l’on trouve c’est les exceptions qui permettent de récupérer des signaux mais que par l’appelant de la méthode qui déclenche le signal.
3 L’héritage simple
Par héritage simple on entend qu’une classe ne peut hériter que d’une seule classe (de manière directe). Par contre cela ne limite en rien le nombre de classes qui peuvent hériter d’une classe. C’est le choix du langage Java qui offre quand même quelques possibilités d’héritage multiple avec les interfaces (spécification d’objets dont on ne donne pas du tout de code).
Avec l’héritage simple, rien de plus simple. On place au début de la mémoire les attributs/méthodes du parent puis après, ceux de la nouvelle classe. Alors l’objet sera interprété comme il faut si on utilise des méthodes des parents qui ne verront que la partie de l’objet qui les intéressent (la suite leur sera comme masquée par leur méconnaissance).
3.1 Les concepts
Un objet ce n’est rien d’autre qu’une zone mémoire où on regroupe un ensemble de variables qui ensemble définissent une entité logique. Un objet peut donc se définir par un pointeur. Tout le reste est dans l’interprétation de ce que l’on trouve à cette adresse. Si je considère qu’il s’agit d’un objet X alors je sais qu’à l’offset 4 par rapport au début de l’objet (par exemple) je vais trouver un entier qui représente une certaine somme sur un compte bancaire.
Maintenant, ce que l’on veut c’est que si l’objet X hérite de la classe CY alors si j’applique une méthode propre aux objet CY elle est la bonne interprétation de la zone mémoire où se trouve notre objet X.
3.2 Une implémentation possible
L’héritage simple ne présente pas trop de problème à mettre en œuvre. Chaque objet ne fait qu’étendre un autre objet. Il suffit donc pour un objet de placer en son début la définition de son parent. Voici un exemple où la classe draw1 hérite de la classe draw.

typedef struct _draw draw; struct _draw { int32 x,y; uint32 width, height; void (* display)(obj_ofs *this); }; typedef struct _draw1 draw1; struct _draw1 { draw parent; uint32 diagonale; void (* fun1)(obj_ofs *this); };
Côté héritage on a bien tout ce que le parent possède plus ce que l’on rajoute. Voyons maintenant comment cela fonctionne. Si on possède un objet de type draw1 appelle vdraw1. Si je veux appeler la méthode fun1 de cet objet il suffit de faire vdraw1->fun1(vdraw1). Rien de plus simple même si cela peut paraître un peu lourd de répéter vdraw1. Pour accéder à l’attribut diagonale de l’objet vdraw1 il suffit de faire vdraw1->diagonale. Néanmoins si on veut respecter l’encapsulage, cela ne peut être fait que dans les méthodes de l’objet.
Maintenant si on veut accéder aux méthodes de l’objet parent, il suffit de faire ((draw *)vdraw1)->display((draw *)vdraw1). En effet comme la partie draw de l’objet vdraw1 est placée au début on peut très bien considérer les objets draw1 comme des objets draw ce que l’on fait par le changement de type avec (draw *). L’objet n’est alors plus considéré que comme un objet draw même si il possède des attributs et des méthodes en plus. La méthode display a été écrite lors de l’écriture de l’objet draw et on voit bien que sans la ré-écrire on peut l’appliquer à nos objet draw1 qui non jamais été pris en compte lors de l’écriture de draw.
Maintenant pourquoi place t’on des pointeurs sur les méthodes des objets ? En effet, on pourrait très bien ne placer que les attributs et utiliser directement les méthodes. D’ailleurs c’est ce qui est fait dans beaucoup de cas quand on développe des objets en C. L’explication vient de la surcharge. En effet, si on veut pouvoir utiliser la surcharge alors cela veut dire que l’on ne peut pas déterminer au moment ou on écrit un appel à une méthode le code qui sera véritablement appelé. C’est d’ailleurs ce qui permet d’avoir une plus grande souplesse.
Si on place un pointeur dans l’objet sur la méthode à appeler alors on sait pour un objet que pour exécuter une méthode, il suffit de trouver son pointeur et d’appeler le code pointé. On a donc bien un moyen de trouver la méthode (le pointeur) mais on ne sait pas laquelle sera effectivement utilisée (déterminée par la valeur du pointeur fixée par la dernière surcharge de l’objet réel). On remarque que cette technique permet même pendant l’exécution de changer le code utilisé mais cela n’est permis par aucun langage objet à l’heure actuelle.
4 L’héritage multiple
Par héritage multiple on désigne les classes qui peuvent hériter de plusieurs autres classes à la fois. Par exemple on peut très bien imaginer une classe hydre_avion qui hériterait à la fois de la classe bateau et avion.
4.1 Les concepts
Le principe reste le même que pour l’héritage simple. Il faut que l’espace mémoire qui représente l’objet soit interprété comme il faut par toutes les méthodes des classes dont hérite un objet. C’est l’implémentation qui devient plus complexe avec des problèmes lorsque l’on hérite plusieurs fois d’un même parent (chose qui était techniquement impossible avec l’héritage simple).
Par rapport à un héritage simple on doit placer une indirection supplémentaire pour accéder aux attributs/méthodes.
En effet, prenons un objet X qui hérite de la classe CY et de la classe CZ. Lorsque l’on passe en paramètre l’objet X à une méthode de la classe CY elle doit pouvoir retrouver sa vision d’un objet Y de même pour CZ. Or si on place tout ce qui concerne la classe CY au début de la mémoire de l’objet puis tout ce qui concerne la classe CZ après. Alors les méthodes de CY et CZ ne peuvent plus utiliser l’offset par rapport au début de l’objet car celui-ci est devenu variable. En effet un objet de la classe CZ aura ses attributs/méthodes au début alors qu’un objet de la classe CX ne les aura pas au début. Pourtant ces deux objets doivent pouvoir être traités par la méthode de la classe CZ. D’où la nécessité d’introduire une indirection avant d’accéder au champs qui nous intéressent. Seulement une classe peut être composée de n’importe quoi, on ne peut donc pas trouver un offset fixe qui indiquerait où aller pour trouver les attributs appartenant à une classe. Il n’y a donc pas plusieurs solutions. Il faut identifier de manière unique les classes et ensuite on devra faire une recherche pour trouver où sont les attributs cherchés en fonction de la classe qui les a déclaré. Pour faire cela, on a évidemment beaucoup de solutions d’implémentation possibles (si vous n’avez pas tout compris cela devrait se clarifier par la suite).
4.2 Une implémentation possible
Tout d’abord on donne une clé (un identifiant) pour chaque classe. On peut faire cela avec une fonction du type suivant.
/* ne pas utiliser directement, utiliser la macro ci dessous */ extern uint32 current_obj_num; /* renvoi un nouveau numero d'identificateur d'objet */ #define object_num_new (++current_obj_num); uint32 draw_type(void) { static uint32 draw_type_num = 0; if(draw_type_num == 0) { draw_type_num = object_num_new; } return(draw_type_num); }
Il faut écrire une fonction dans le même style pour chaque classe (ici cela a été fait pour la classe draw). La variable current_obj_num ainsi que la macro permettent de générer des numéros uniques pour chaque classe.
Un objet sera alors défini par un tableau d’identificateurs associés chacun à un pointeur. Le pointeur permet alors de savoir où sont les champs (attributs et méthodes) propres à la classe d’identificateur (celui associé au pointeur). Pour retrouver les champs propres à une classe il suffit de parcourir ce tableau à la recherche de l’identificateur de la classe puis de suivre le pointeur associé. Pour savoir si on a parcouru tout le tableau on placera à la fin de celui-ci un identificateur 0 (ou un pointeur NULL). Identificateur qui ne peut donc pas être utilisé par les classes. Ce délimiteur de fin nous permettra de vérifier la validité d’une opération (une erreur dynamique sur le typage de l’objet). Si on considérait que ce type d’erreur ne se produit pas on est alors sûr de trouver l’identifiant cherché avant la fin et on peut se passer de ce délimiteur. Mais cela nous permet aussi de tester l’appartenance d’un objet à une classe durant l’exécution (avec des opérateurs comme instanceof en Java).
Voici la structure du tableau.
typedef struct _obj_ofs obj_ofs; struct _obj_ofs { uint32 obj_type; pointer ofs; };
Un objet est alors défini par obj_ofs * (un tableau). Par souci de ne pas trop fragmenter la mémoire et de ne pas générer trop d’allocations système, les champs spécifiques à chaque classe seront placés après le tableau dans la mémoire.
Comme vous l’avez compris, les champs seront isolés en fonction de la première classe où ils apparaissent. Pourquoi fait on cela ? En fait, chaque objet doit pouvoir être vu comme un objet appartenant à n’importe quelle classe parente. Or une méthode qui sait traiter un objet d’une classe connaît toute les classes qui lui sont parentes mais pas celles qui peuvent hériter d’elle. Elle a donc toutes les informations statiquement pour retrouver des champs qu’elle possède par héritage et n’aura donc pas de problèmes pour retrouver l’adresse de base des champs déclarés dans cette classe et accéder aux champs. Par contre elle ne connaît pas les classes qui héritent de sa classe (leurs identifiants et donc leurs adresses de base). Donc on ne doit pas placer des champs hérités dans un espace mémoire non accessible par les parents. C’est pourquoi, pour qu’ils soient toujours accessibles quand cela est possible, on les déclarent dans l’espace mémoire de la première classe qui les fait apparaître (ainsi toutes les classes qui héritent de cette classe savent qu’il faut chercher avec la clé de leur parent).
On pourrait toujours évidemment créer des copies des champs des parents (chaque classe ayant accès à tout les champs possibles dans son espace) mais il faudrait alors conserver la cohérence entre les copies (modifier l’un revient à modifier toutes les copies) ce qui est impossible.
Ce qui nous amène à la solution d’un des problèmes de l’héritage multiple. En effet, lorsqu’une classe hérite plusieurs fois d’une classe parente on ne peut pas stocker les informations de la classe dont on hérite de manière multiple plusieurs fois. Les méthodes des classes parentes qui accéderait à des objets de cette classe ne peuvent voir qu’un exemplaire de la classe multiple (en effet si je décide de voir mon objet comme un objet de la classe dont on hérite de manière multiple, je n’ai accès qu’à un objet et pas plusieurs). Il n’y a donc qu’une solution : n’intégrer qu’une seule fois cet héritage (par priorité par exemple). Cependant on peut toujours au niveau de la nouvelle classe qui hérite de manière multiple d’une classe, copier les champs qui ne seront pas pris dans le mécanisme de priorité pour ne pas perdre les surcharges des méthodes (par contre cela n’a absolument aucun intérêt pour les attributs et même aucun sens en terme d’objet). Ceci peut être présenté au programmeur objet à travers un mécanisme de renommage (qui peut renommer aussi des méthodes qui n’ont pas soufferts de ce problème en créant dans la nouvelle classe un nouveau pointeur de méthode). On l’a donc bien compris la duplication des champs d’une classe parent n’existe pas, il y a forcément un des héritages qui est prioritaire même si on peut toujours inventer un système qui dynamiquement changerait la priorité (là on commence à entrer dans la folie).
Bon, vite quelques exemples pratiques pour faire passer tout cela. Supposons que l’on possède une classe draw qui hérite de la classe object. Les champs spécifiques de chaque classe sont définis comme suit.
typedef struct _object object; struct _object { void (* free)(obj_ofs *this); }; typedef struct _draw draw; struct _draw { int32 x,y; uint32 width, height; void (* display)(obj_ofs *this); };
Les objets object possèdent donc qu’une méthode (free) et les objets draw possèdent les attributs x, y, width, height, la méthode free (héritée de la classe object) et la méthode display.
Voilà pour la description des objets, voyons maintenant comment ils sont représentés en mémoire.
| Un objet Object | Un objet Draw | |
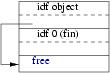 |
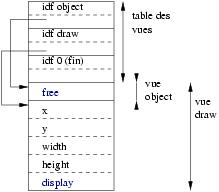 |
Chaque objet peut donc bien avoir accès à tout les champs. On remarque que pour l’objet draw, la vue draw est composée par la partie correspondante aux champs draw et aussi de manière implicite la vue object. Dans cet exemple les champs object et draw de l’objet draw sont consécutifs mais on verra dans l’exemple suivant que ce n’est pas forcément le cas en cas d’héritage multiple.
Donc voici un autre exemple un peu plus compliqué:
typedef struct _object object; struct _object { void (* free)(obj_ofs *this); }; typedef struct _draw draw; struct _draw { int32 x,y; uint32 width, height; void (* display)(obj_ofs *this); }; typedef struct _draw1 draw1; struct _draw1 { uint32 diagonale; void (* fun1)(obj_ofs *this); }; typedef struct _draw2 draw2; struct _draw2 { void (* fun2)(obj_ofs *this); }; typedef struct _draw3 draw3; struct _draw3 { int32 draw3_att; void (* fun3)(obj_ofs *this); };
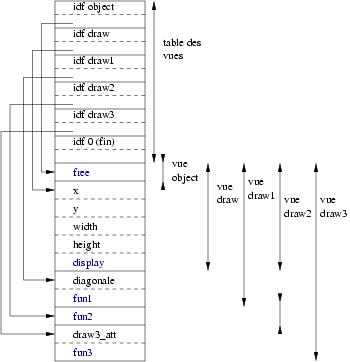
Dans cet exemple, la vue draw2 n’est pas consécutive. Prenons maintenant quelques exemples d’utilisation.
Si on veut accéder à l’attribut « diagonale » des objets appartenant à la classe draw1 et toutes celles qui en héritent (draw3 ici), on doit parcourir la table des vues à la recherche de l’identifiant draw1 (première classe à déclarer ce champ). Une fois en possession de l’adresse de base correspondante, on y ajoute l’offset pour atteindre l’attribut « diagonale » (offset constant et connu de manière statique à la génération du code car la définition des champs d’une classe n’est jamais remise en cause). Avec l’adresse de base plus l’offset on trouve la zone mémoire qui correspond à l’attribut « diagonale ».
Si maintenant on veut exécuter la méthode fun3 de classe draw3 on parcourt la table des vues à la recherche de l’identifiant draw3 (première classe à déclarer cette méthode). On retire l’adresse de base, puis on additionne l’offset ce qui nous donne accès au pointeur sur la méthode fun3. Après, il suffit de faire un appel à cette adresse. On voit donc bien que l’appel des méthodes est un peu plus long que le simple déroutement à une adresse dans les langages non objets.
4.2.1 L’héritage
Dans chaque classe on défini un ou des constructeurs qui ont pour but de créer des objets de cette classe (sauf dans le cas des classes abstraites). C’est dans cette procédure que l’on alloue la mémoire nécessaire à l’objet que l’on crée. On alloue la place pour tous les parents plus pour les champs nouvellement définis dans notre classe. On rempli aussi la table des vues qui indiquera à chaque classe ou sont ses champs spécifiques. Ensuite, on initialise l’objet en appelant les constructeurs de chaque classe parentes en commencant par la plus lointaine (classe dont tout le monde hérite) pour que la surcharge puisse fonctionner.
Les construteurs sont des fonctions qui font pointer les pointeurs de fonctions sur les implémentations (ceci est caché dans les langages objets). C’est aussi ici que l’on initialise les attributs si nécessaire (c’est le programmeur qui détermine les initialisations).
Au final, notre objet posséde bien tous les attributs et méthodes des ses parents et de sa classe. On a donc bien l’héritage.
4.2.2 Le polymorphisme
Avec notre système d’indirection un objet qui hérite d’une classe peut toujours être considéré comme un objet de cette classe. Les objets d’une classe peuvent donc bien revêtir plusieurs formes réelles.
4.2.3 La surcharge
La surcharge est une chose assez aisée. Il suffit d’accéder au pointeur sur la fonction que l’on veut surcharger (en y accédant comme n’importe quel attribut par le système d’indirection) et de changer sa valeur pour le faire pointer sur la nouvelle implémentation.
4.2.4 Les méthodes abstraites
Dans notre implémentation de l’héritage multiple, cela revient à déclarer un pointeur sur la fonction voulue (comme pour les méthodes normales) en le faisant pointer sur n’importe quoi. Ceci, au niveau de la classe abstraite (celle qui ne déclare pas le code) qui est la première à faire aparaitre ce champs même si elle n’en donne pas le code.
Ensuite il suffira pour les héritiers d’accéder à ce champ de leur parent pour le faire pointer sur l’implémentation qu’ils ont faite. C’est exactement le même principe que pour une surcharge de fonction sauf que dans la surcharge, le pointeur pointait sur une adresse de fonction valide.
4.3 Les optimisations possibles
Le principal problème c’est le temps d’accès à un champ. Il faut tout d’abord parcourir un tableau pour chercher l’adresse des champs spécifiques à une classe. Ensuite seulement on accède au champ souhaité (en additionnant son offset à l’adresse de base trouvée).
La première chose à faire c’est de déterminer toutes les adresses de bases qui vont servir en un parcours du tableau au début des méthodes. Malheureusement cela est encore assez cher pour les petites méthodes (car le temps de parcours n’est pas proportionnel au nombre d’accès aux champs).
Une solution pour accélérer consiste à utiliser une fonction de hachage sur la profondeur de l’héritage. En effet, la plupart du temps on a un héritage simple qui est grandement accéléré par cette méthode.
Pour faire cela, on place un tableau de pointeur uniquement au début. Ensuite en fonction des champs que l’on veut accéder et de la profondeur de la classe (nombre de niveau de parents) qui le défini on trouve une adresse de base (c’est donc immédiat). Comme plusieurs classes parent peuvent se trouver au même niveau d’héritage on place à l’adresse donnée par le pointeur le numéro de la classe en question et un pointeur sur la classe suivante au même niveau d’héritage. On chaine les classes au même niveau d’héritage (méthode classique dans le hachage).
Pour déterminer l’identifiant d’une classe on peut utiliser une fonction mais on peut aussi déterminer l’identificateur pendant la phase de compilation. On doit par contre avoir un générateur d’identifiant pour les classes qui peuvent être chargées dynamiquement pendant l’exécution. Les identifiants doivent alors être choisis au chargement et placés dans des variables. Si on ne charge pas des classes dynamiquement alors on peut inclure les valeurs des identifiants dans le code (sans variables).
Encore une chose. On ne peut pas accéder directement aux méthodes des objets (à cause des tables des identifiants ou du hachage qui peut échouer et donner lieu à un chaînage) il faut donc créer une fonction pour accéder à chaque méthode. Néanmoins, si on veut économiser la taille du programme (et donc la mémoire) on peut créer une fonction générique à laquelle on passe tous les paramètres, leurs types , le nombre, la classe (son identifiant) et l’offset de la méthode dans la classe. Cette fonction s’occupe alors du reste (hachage ou parcourt du tableau…). Cela complique la programmation (surtout en C ou Pascal…) mais un compilateur s’en débrouillera très bien.
5 Conclusion
Si les langages objets apportent une plus grande souplesse sur la définition d’un programme en le découpant en unités logiques facilement réutilisables. Ils génèrent aussi un sur-coût dans le traitement de cette mécanique. Mais la lourdeur (taille en nombre de lignes) des programmes actuels et les contraintes économiques de réutilisabilité en font des outils très utilisés.
J’espère que ce document vous aura permis d’en apprendre un peu plus sur les langages objets et sur les problèmes de réalisation qu’ils génèrent.
Pour fixer un peu plus tout cela, vous trouverez en annexe un programme C qui donne une implémentation de l’exemple d’héritage multiple.
6 Annexe
documents joints:
- draw.c.html (HTML – 18.4 ko)
- draw.h.html (HTML – 3.1 ko)
- draw1.c.html (HTML – 26.4 ko)
- draw1.h.html (HTML – 2.7 ko)
- draw2.c.html (HTML – 22.8 ko)
- draw2.h.html (HTML – 2.6 ko)
- draw3.c.html (HTML – 23.8 ko)
- draw3.h.html (HTML – 2.8 ko)
- general.h.html (HTML – 2.5 ko)
- Makefile.html (HTML – 2.1 ko)
- object.c.html (HTML – 10.6 ko)
- object.h.html (HTML – 3.5 ko)
- object_test.c.html (HTML – 7.3 ko)